WebScraper is intended for scanning and extracting data from websites. This means that the tool can crawl web pages starting from a given URL and report a list of their associated data. The application is mainly intended for professional use, which is reflected in the look and feel of its interface. Fortunately, it is well documented, and you can consult its Quick Start guide or the user manual as well as watch its video demo.
Using the tool consists in three steps: entering the desired starting URL, configuring the output and processing the data obtained. There is the option to switch to a complex setup if you need more customization. There are lots of options to configure, which is why the attempt to make things easier by compartmentalizing them in tabs is greatly appreciated.
In this regard, the Scan tab allows controlling the scope of the scan by establishing limits via black and white lists. Moreover, it lets you set the number of simultaneous threads. Besides, you should go there to enter authentication data for those sites requiring a login. You can notice that there is only one supported authentication method, which works for most but not all the sites.
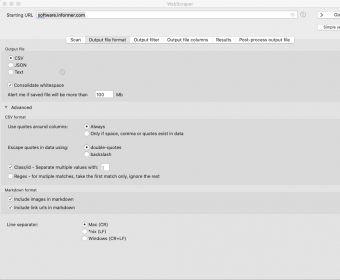
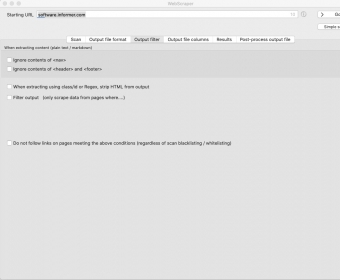
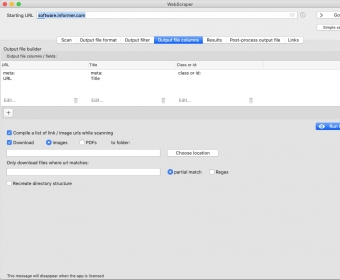
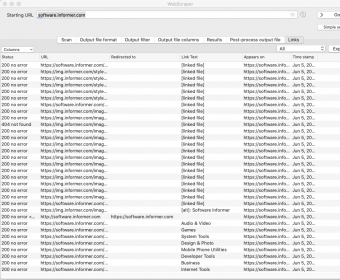
Then, if you want to configure the format of the results file before exporting, you can switch to the Output File Format tab. Similarly, the Output Filter and the Output File Columns tabs are intended for limiting scraping to sections or specific pages as well as setting the columns to show. Finally, there is the Results tab, which allows previewing the results in a table form. more

Comments