The UAM CorpusTool is a state-of-the-art environment for annotation of text corpora. So, whether you are annotating a corpus as part of a linguistic study, or building a training set for use in statistical language processing, this is the tool for you.
Powerful Annotation Tool
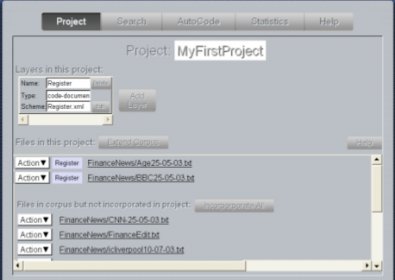
Annotation of multiple texts using the same annotation schemes, of your design.
Annotation of each text at multiple levels (e.g., NP, Clause, Sentence, whole document).
Searching for instances across levels, e.g., finite-clause containing company-np, or future-clause in introduction.
Comparative statistics across subsets, e.g., contrasting conversational patterns used by male and female speakers.
All annotation is in stored in XML files, meaning that your annotations can more easily be shared with other applications.
We use "stand-off" XML: the annotation files do not contain the text, just pointers to the text. This allows for multiple overlapping analyses of the same text, not so easy in standard XML.
Comments